Read From Bigquery Apache Beam
Read From Bigquery Apache Beam - How to output the data from apache beam to google bigquery. Working on reading files from multiple folders and then output the file contents with the file name like (filecontents, filename) to bigquery in apache beam. Similarly a write transform to a bigquerysink accepts pcollections of dictionaries. Web i'm trying to set up an apache beam pipeline that reads from kafka and writes to bigquery using apache beam. I have a gcs bucket from which i'm trying to read about 200k files and then write them to bigquery. Web in this article you will learn: Union[str, apache_beam.options.value_provider.valueprovider] = none, validate: Public abstract static class bigqueryio.read extends ptransform < pbegin, pcollection < tablerow >>. Web the default mode is to return table rows read from a bigquery source as dictionaries. Web the runner may use some caching techniques to share the side inputs between calls in order to avoid excessive reading:::
I am new to apache beam. To read an entire bigquery table, use the from method with a bigquery table name. I'm using the logic from here to filter out some coordinates: I have a gcs bucket from which i'm trying to read about 200k files and then write them to bigquery. Public abstract static class bigqueryio.read extends ptransform < pbegin, pcollection < tablerow >>. When i learned that spotify data engineers use apache beam in scala for most of their pipeline jobs, i thought it would work for my pipelines. See the glossary for definitions. The structure around apache beam pipeline syntax in python. Web the runner may use some caching techniques to share the side inputs between calls in order to avoid excessive reading::: Can anyone please help me with my sample code below which tries to read json data using apache beam:
Web the runner may use some caching techniques to share the side inputs between calls in order to avoid excessive reading::: I'm using the logic from here to filter out some coordinates: In this blog we will. When i learned that spotify data engineers use apache beam in scala for most of their pipeline jobs, i thought it would work for my pipelines. To read data from bigquery. Similarly a write transform to a bigquerysink accepts pcollections of dictionaries. As per our requirement i need to pass a json file containing five to 10 json records as input and read this json data from the file line by line and store into bigquery. To read an entire bigquery table, use the from method with a bigquery table name. Web i'm trying to set up an apache beam pipeline that reads from kafka and writes to bigquery using apache beam. Read what is the estimated cost to read from bigquery?

Apache Beam rozpocznij przygodę z Big Data Analityk.edu.pl
Web for example, beam.io.read(beam.io.bigquerysource(table_spec)). How to output the data from apache beam to google bigquery. 5 minutes ever thought how to read from a table in gcp bigquery and perform some aggregation on it and finally writing the output in another table using beam pipeline? In this blog we will. Main_table = pipeline | 'verybig' >> beam.io.readfrobigquery(.) side_table =.

Apache Beam Tutorial Part 1 Intro YouTube
See the glossary for definitions. Web read files from multiple folders in apache beam and map outputs to filenames. Similarly a write transform to a bigquerysink accepts pcollections of dictionaries. Working on reading files from multiple folders and then output the file contents with the file name like (filecontents, filename) to bigquery in apache beam. Web the default mode is.

Apache Beam Explained in 12 Minutes YouTube
Web i'm trying to set up an apache beam pipeline that reads from kafka and writes to bigquery using apache beam. Web this tutorial uses the pub/sub topic to bigquery template to create and run a dataflow template job using the google cloud console or google cloud cli. As per our requirement i need to pass a json file containing.
How to submit a BigQuery job using Google Cloud Dataflow/Apache Beam?
To read an entire bigquery table, use the table parameter with the bigquery table. Web i'm trying to set up an apache beam pipeline that reads from kafka and writes to bigquery using apache beam. This is done for more convenient programming. I am new to apache beam. Web using apache beam gcp dataflowrunner to write to bigquery (python) 1.

Apache Beam介绍
Web for example, beam.io.read(beam.io.bigquerysource(table_spec)). Web read files from multiple folders in apache beam and map outputs to filenames. I initially started off the journey with the apache beam solution for bigquery via its google bigquery i/o connector. To read data from bigquery. Web this tutorial uses the pub/sub topic to bigquery template to create and run a dataflow template job.

How to setup Apache Beam notebooks for development in GCP
I am new to apache beam. The structure around apache beam pipeline syntax in python. Web this tutorial uses the pub/sub topic to bigquery template to create and run a dataflow template job using the google cloud console or google cloud cli. Working on reading files from multiple folders and then output the file contents with the file name like.
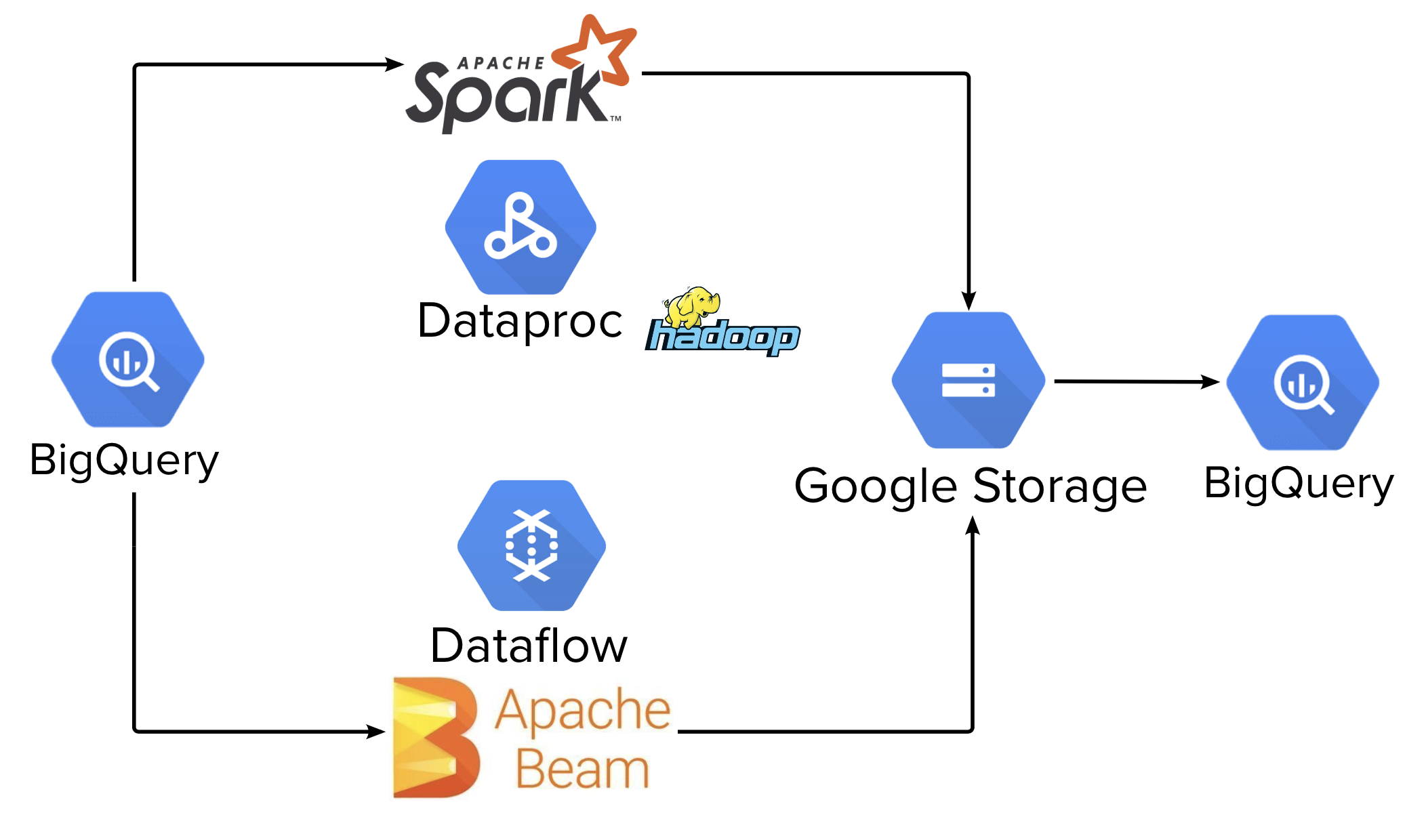
One task — two solutions Apache Spark or Apache Beam? · allegro.tech
Web this tutorial uses the pub/sub topic to bigquery template to create and run a dataflow template job using the google cloud console or google cloud cli. To read an entire bigquery table, use the table parameter with the bigquery table. The problem is that i'm having trouble. Read what is the estimated cost to read from bigquery? I am.
GitHub jo8937/apachebeamdataflowpythonbigquerygeoipbatch
I am new to apache beam. Web for example, beam.io.read(beam.io.bigquerysource(table_spec)). In this blog we will. The structure around apache beam pipeline syntax in python. Read what is the estimated cost to read from bigquery?
Google Cloud Blog News, Features and Announcements
Can anyone please help me with my sample code below which tries to read json data using apache beam: I am new to apache beam. Web apache beam bigquery python i/o. The problem is that i'm having trouble. I initially started off the journey with the apache beam solution for bigquery via its google bigquery i/o connector.

Apache Beam チュートリアル公式文書を柔らかく煮込んでみた│YUUKOU's 経験値
Public abstract static class bigqueryio.read extends ptransform < pbegin, pcollection < tablerow >>. As per our requirement i need to pass a json file containing five to 10 json records as input and read this json data from the file line by line and store into bigquery. The following graphs show various metrics when reading from and writing to bigquery..
Web Read Csv And Write To Bigquery From Apache Beam.
When i learned that spotify data engineers use apache beam in scala for most of their pipeline jobs, i thought it would work for my pipelines. To read an entire bigquery table, use the from method with a bigquery table name. The problem is that i'm having trouble. Similarly a write transform to a bigquerysink accepts pcollections of dictionaries.
Main_Table = Pipeline | 'Verybig' >> Beam.io.readfrobigquery(.) Side_Table =.
Web apache beam bigquery python i/o. To read an entire bigquery table, use the table parameter with the bigquery table. How to output the data from apache beam to google bigquery. I have a gcs bucket from which i'm trying to read about 200k files and then write them to bigquery.
I'm Using The Logic From Here To Filter Out Some Coordinates:
The following graphs show various metrics when reading from and writing to bigquery. I initially started off the journey with the apache beam solution for bigquery via its google bigquery i/o connector. To read data from bigquery. Web for example, beam.io.read(beam.io.bigquerysource(table_spec)).
Web Using Apache Beam Gcp Dataflowrunner To Write To Bigquery (Python) 1 Valueerror:
I am new to apache beam. Working on reading files from multiple folders and then output the file contents with the file name like (filecontents, filename) to bigquery in apache beam. Web the runner may use some caching techniques to share the side inputs between calls in order to avoid excessive reading::: Union[str, apache_beam.options.value_provider.valueprovider] = none, validate: