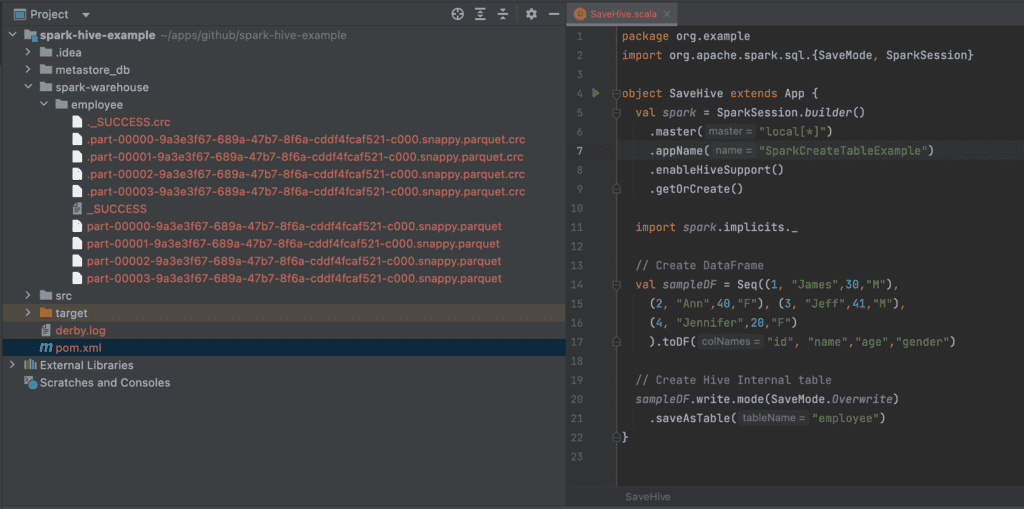
Spark Read Table
Spark Read Table - Reading tables and filtering by partition ask question asked 3 years, 9 months ago modified 3 years, 9 months ago viewed 3k times 2 i'm trying to understand spark's evaluation. Web read a table into a dataframe. Web the core syntax for reading data in apache spark dataframereader.format(…).option(“key”, “value”).schema(…).load() dataframereader is the foundation for reading data in spark, it can be accessed via the attribute spark.read… This includes reading from a table, loading data from files, and operations that transform data. The case class defines the schema of the table. // note you don't have to provide driver class name and jdbc url. Usage spark_read_table ( sc, name, options = list (), repartition = 0 , memory = true , columns = null ,. The spark catalog is not getting refreshed with the new data inserted into the external hive table. Often we have to connect spark to one of the relational database and process that data. Reads from a spark table into a spark dataframe.
Index_colstr or list of str, optional, default: // loading data from autonomous database at root compartment. Many systems store their data in rdbms. Web spark sql provides spark.read ().csv (file_name) to read a file or directory of files in csv format into spark dataframe, and dataframe.write ().csv (path) to write to a. Web parquet is a columnar format that is supported by many other data processing systems. Loading data from an autonomous database at the root compartment: Web example code for spark oracle datasource with java. Usage spark_read_table ( sc, name, options = list (), repartition = 0 , memory = true , columns = null ,. The following example uses a.</p> Spark sql also supports reading and writing data stored in apache hive.
Index_colstr or list of str, optional, default: Web this is done by setting spark.sql.hive.convertmetastoreorc or spark.sql.hive.convertmetastoreparquet to false. Web spark filter () or where () function is used to filter the rows from dataframe or dataset based on the given one or multiple conditions or sql expression. Web the core syntax for reading data in apache spark dataframereader.format(…).option(“key”, “value”).schema(…).load() dataframereader is the foundation for reading data in spark, it can be accessed via the attribute spark.read… The names of the arguments to the case class. Read a spark table and return a dataframe. However, since hive has a large number of dependencies, these dependencies are not included in the default spark. Web read a table into a dataframe. Union [str, list [str], none] = none) → pyspark.pandas.frame.dataframe [source] ¶. Loading data from an autonomous database at the root compartment:
Spark SQL Read Hive Table Spark By {Examples}
Web reads from a spark table into a spark dataframe. This includes reading from a table, loading data from files, and operations that transform data. // note you don't have to provide driver class name and jdbc url. Index column of table in spark. Usage spark_read_table( sc, name, options = list(), repartition = 0, memory = true, columns =.

Spark Plug Reading 101 Don’t Leave HP On The Table! Hot Rod Network
Web the core syntax for reading data in apache spark dataframereader.format(…).option(“key”, “value”).schema(…).load() dataframereader is the foundation for reading data in spark, it can be accessed via the attribute spark.read… Interacting with different versions of hive metastore; Web the scala interface for spark sql supports automatically converting an rdd containing case classes to a dataframe. Many systems store their data in.

Spark SQL Tutorial 2 How to Create Spark Table In Databricks
Reads from a spark table into a spark dataframe. Specifying storage format for hive tables; Web most apache spark queries return a dataframe. The case class defines the schema of the table. In order to connect to mysql server from apache spark…
My spark table. Miata Turbo Forum Boost cars, acquire cats.
You can use where () operator instead of the filter if you are. The following example uses a.</p> In the simplest form, the default data source ( parquet. You can also create a spark dataframe from a list or a. Web read data from azure sql database write data into azure sql database show 2 more learn how to connect.
Spark Table Miata Turbo Forum Boost cars, acquire cats.
You can easily load tables to dataframes, such as in the following example: Union [str, list [str], none] = none) → pyspark.pandas.frame.dataframe [source] ¶. We have a streaming job that gets some info from a kafka topic and queries the hive table. // loading data from autonomous database at root compartment. Index column of table in spark.

The Spark Table Curved End Table or Night Stand dust furniture*
Web the core syntax for reading data in apache spark dataframereader.format(…).option(“key”, “value”).schema(…).load() dataframereader is the foundation for reading data in spark, it can be accessed via the attribute spark.read… Spark sql also supports reading and writing data stored in apache hive. However, since hive has a large number of dependencies, these dependencies are not included in the default spark. In.
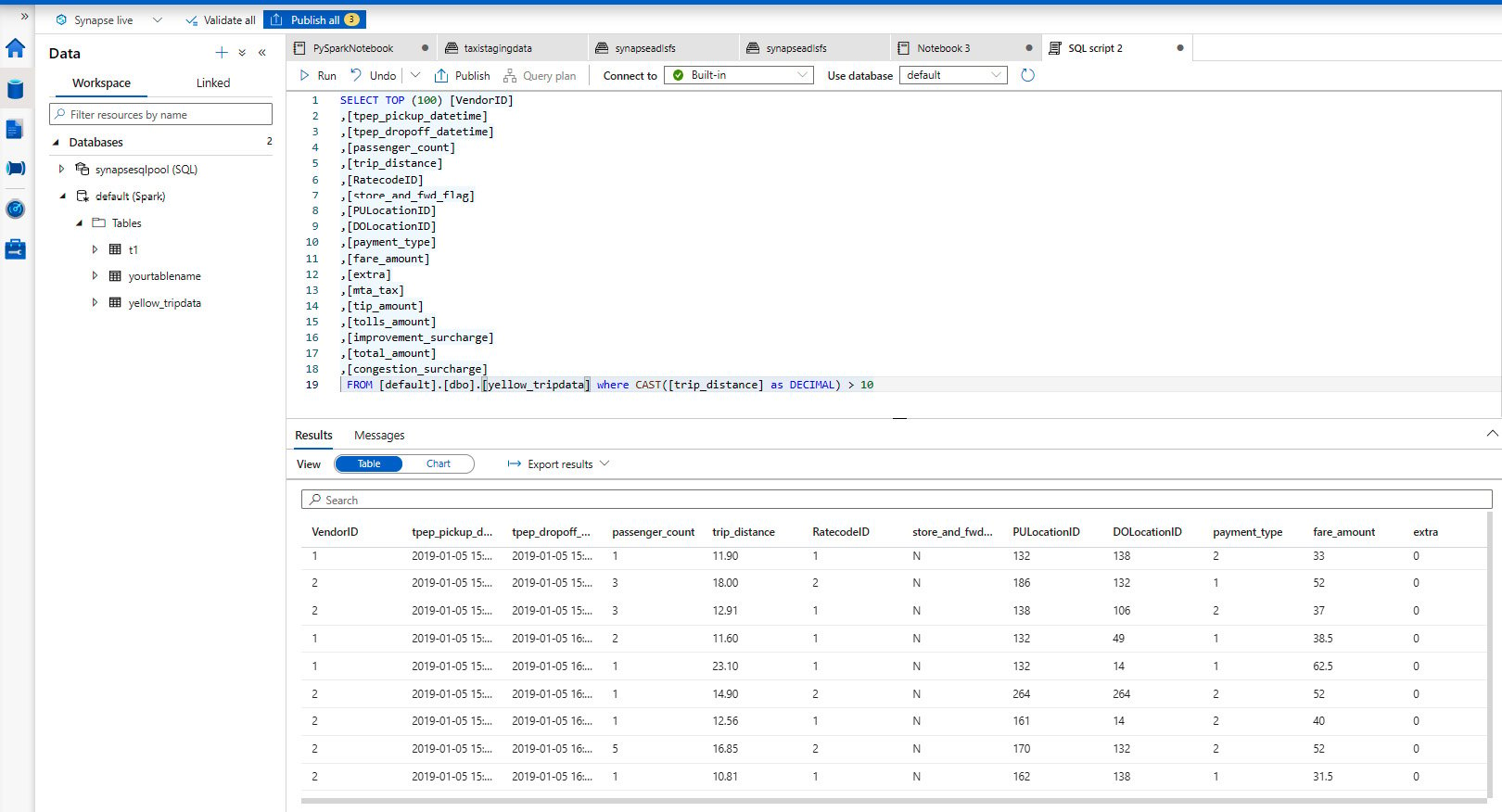
Reading and writing data from ADLS Gen2 using PySpark Azure Synapse
Union [str, list [str], none] = none) → pyspark.pandas.frame.dataframe [source] ¶. Web the scala interface for spark sql supports automatically converting an rdd containing case classes to a dataframe. The names of the arguments to the case class. Web reads from a spark table into a spark dataframe. The spark catalog is not getting refreshed with the new data inserted.

Spark Plug Reading 101 Don’t Leave HP On The Table! Hot Rod Network
// loading data from autonomous database at root compartment. Web reading data from sql tables in spark by mahesh mogal sql databases or relational databases are around for decads now. Spark sql also supports reading and writing data stored in apache hive. Azure databricks uses delta lake for all tables by default. In the simplest form, the default data source.

Spark Plug Reading 101 Don’t Leave HP On The Table!
Reading tables and filtering by partition ask question asked 3 years, 9 months ago modified 3 years, 9 months ago viewed 3k times 2 i'm trying to understand spark's evaluation. Web read data from azure sql database write data into azure sql database show 2 more learn how to connect an apache spark cluster in azure hdinsight with azure sql.

Spark Essentials — How to Read and Write Data With PySpark Reading
The following example uses a.</p> Many systems store their data in rdbms. Spark sql also supports reading and writing data stored in apache hive. Reading tables and filtering by partition ask question asked 3 years, 9 months ago modified 3 years, 9 months ago viewed 3k times 2 i'm trying to understand spark's evaluation. The case class defines the schema.
Loading Data From An Autonomous Database At The Root Compartment:
You can easily load tables to dataframes, such as in the following example: Interacting with different versions of hive metastore; Usage spark_read_table ( sc, name, options = list (), repartition = 0 , memory = true , columns = null ,. Web parquet is a columnar format that is supported by many other data processing systems.
That's One Of The Big.
Web the scala interface for spark sql supports automatically converting an rdd containing case classes to a dataframe. There is a table table_name which is partitioned by partition_column. In this article, we are going to learn about reading data from sql tables in spark. Union [str, list [str], none] = none) → pyspark.pandas.frame.dataframe [source] ¶.
Web Read Data From Azure Sql Database Write Data Into Azure Sql Database Show 2 More Learn How To Connect An Apache Spark Cluster In Azure Hdinsight With Azure Sql Database.
Spark sql provides support for both reading and writing parquet files that automatically preserves the schema of the original data. You can use where () operator instead of the filter if you are. Spark sql also supports reading and writing data stored in apache hive. Web aug 21, 2023.
Often We Have To Connect Spark To One Of The Relational Database And Process That Data.
Web read a table into a dataframe. // note you don't have to provide driver class name and jdbc url. We have a streaming job that gets some info from a kafka topic and queries the hive table. Read a spark table and return a dataframe.